|
Data-Efficient Policy Evaluation Through Behavior Policy Search
Josiah P. Hanna, Yash Chandak, Philip S. Thomas, Martha White, Peter Stone, Scott Niekum
Journal of Machine Learning Research (JMLR)
Abstract
We consider the task of evaluating a policy for a \textit{Markov decision process} (MDP). The standard unbiased technique for evaluating a policy is to deploy the policy and observe its performance. We show that the data collected from deploying a different policy, commonly called the \textit{behavior policy}, can be used to produce unbiased estimates with lower mean squared error than this standard technique. We derive an analytic expression for a \textit{minimal variance behavior policy} -- a behavior policy that minimizes the mean squared error of the resulting estimates. Because this expression depends on terms that are unknown in practice, we propose a novel policy evaluation sub-problem, \textit{behavior policy search}: searching for a behavior policy that reduces mean squared error. We present two behavior policy search algorithms and empirically demonstrate their effectiveness in lowering the mean squared error of policy performance estimates.
|
|
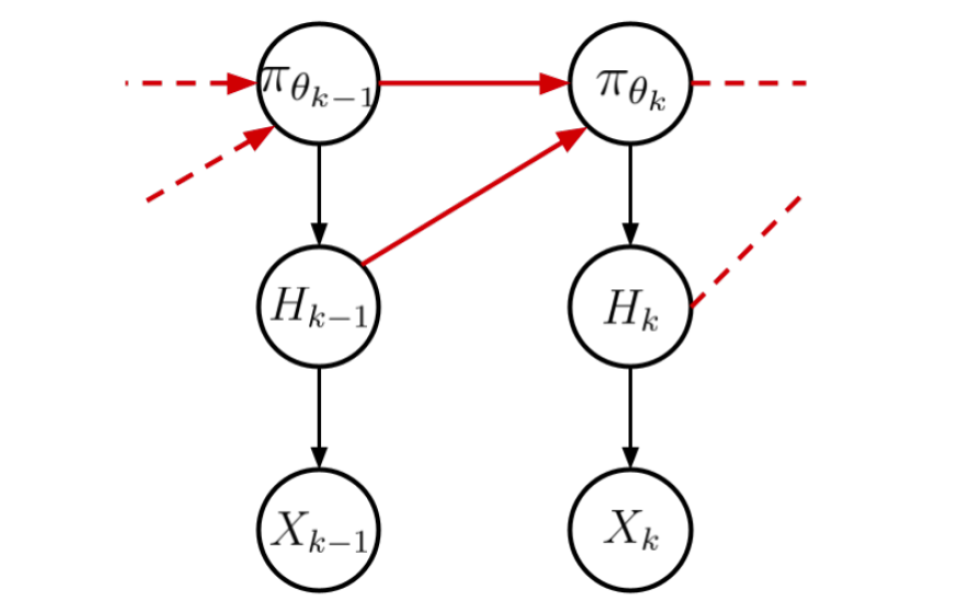
Information Directed Tree Search: Reasoning and Planning with Language Agents
Yash Chandak, HyunJi Nam, Allen Nie, Jonathan Lee, Emma Brunskill
Bayesian Decision-making and Uncertainty Workshop at Neural Information Processing Systems (BDU@NeurIPS 2024)
Abstract | Arxiv
Solving challenging tasks often require agentic formulation of language models that can do multi-step reasoning and progressively solve the task by collecting various feedback. For computational efficiency, it may be advantageous to quantify the information associated with different feedback and guide the search such that the solution can be obtained quickly. To explore this possibility, we take a Bayesian approach and propose an \textit{information directed tree search} (IDTS) algorithm that makes use of in-context learning to approximate the information associated with different feedback. We explore the effectivity of IDTS on challenging tasks involving programming, formal math, and natural language. Interestingly, while we find advantages over simple uniform search methods, the proposed approach is about comparable to MCTS even though it explores different paths. We discuss some possibilities for our findings and highlight open questions for future work.
|
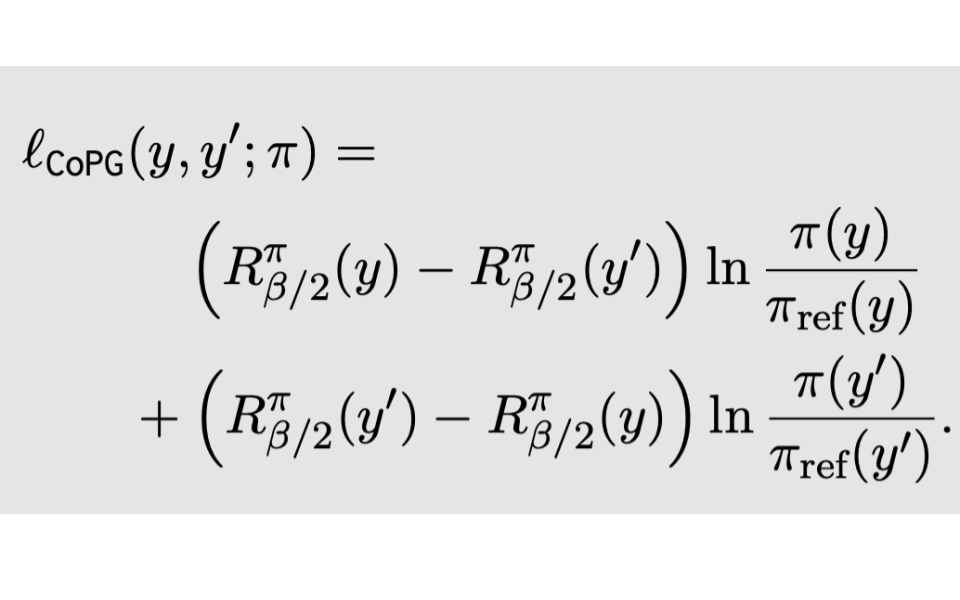
|
Contrastive Policy Gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion
Yannis Flet-Berliac, Nathan Grinsztajn, Florian Strub, Eugene Choi, Chris Cremer, Arash Ahmadian, Yash Chandak, Mohammad Gheshlaghi Azar, Olivier Pietquin, Matthieu Geist
Conference on Empirical Methods in Natural Language Processing (EMNLP 2024)
Abstract | Arxiv
Reinforcement Learning (RL) has been used to finetune Large Language Models (LLMs) using a reward model trained from preference data, to better align with human judgment. The recently introduced direct alignment methods, which are often simpler, more stable, and computationally lighter, can more directly achieve this. However, these approaches cannot optimize arbitrary rewards, and the preference-based ones are not the only rewards of interest for LLMs (eg., unit tests for code generation or textual entailment for summarization, among others). RL-finetuning is usually done with a variation of policy gradient, which calls for on-policy or near-on-policy samples, requiring costly generations. We introduce Contrastive Policy Gradient, or CoPG, a simple and mathematically principled new RL algorithm that can estimate the optimal policy even from off-policy data. It can be seen as an off-policy policy gradient approach that does not rely on important sampling techniques and highlights the importance of using (the right) state baseline. We show this approach to generalize the direct alignment method IPO (identity preference optimization) and classic policy gradient. We experiment with the proposed CoPG on a toy bandit problem to illustrate its properties, as well as for finetuning LLMs on a summarization task, using a learned reward function considered as ground truth for the purpose of the experiments.
|
|
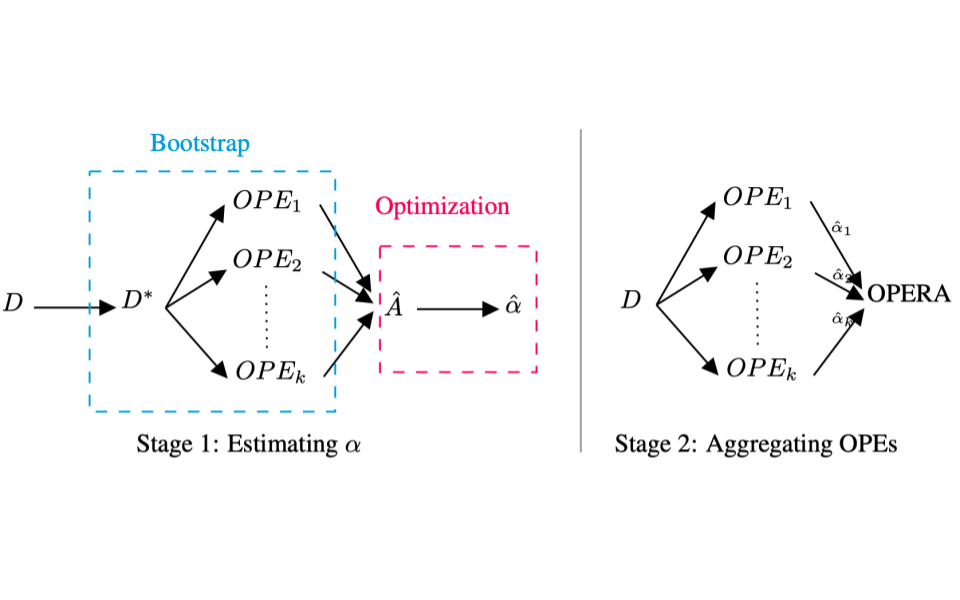
OPERA: Automatic Offline Policy Evaluation with Re-weighted Aggregates of Multiple Estimators
Allen Nie,
Yash Chandak,
Christina J Yuan,
Anirudhan Badrinath,
Yannis Flet-Berliac,
Emma Brunskill.
Thirty-eighth Conference on Neural Information Processing Systems (NeurIPS 2024)
Abstract | Arxiv
Offline policy evaluation (OPE) allows us to evaluate and estimate a new sequential decision-making policy's performance by leveraging historical interaction data collected from other policies. Evaluating a new policy online without a confident estimate of its performance can lead to costly, unsafe, or hazardous outcomes, especially in education and healthcare. Several OPE estimators have been proposed in the last decade, many of which have hyperparameters and require training. Unfortunately, choosing the best OPE algorithm for each task and domain is still unclear. In this paper, we propose a new algorithm that adaptively blends a set of OPE estimators given a dataset without relying on an explicit selection using a statistical procedure. We prove that our estimator is consistent and satisfies several desirable properties for policy evaluation. Additionally, we demonstrate that when compared to alternative approaches, our estimator can be used to select higher-performing policies in healthcare and robotics. Our work contributes to improving ease of use for a general-purpose, estimator-agnostic, off-policy evaluation framework for offline RL.
|
|
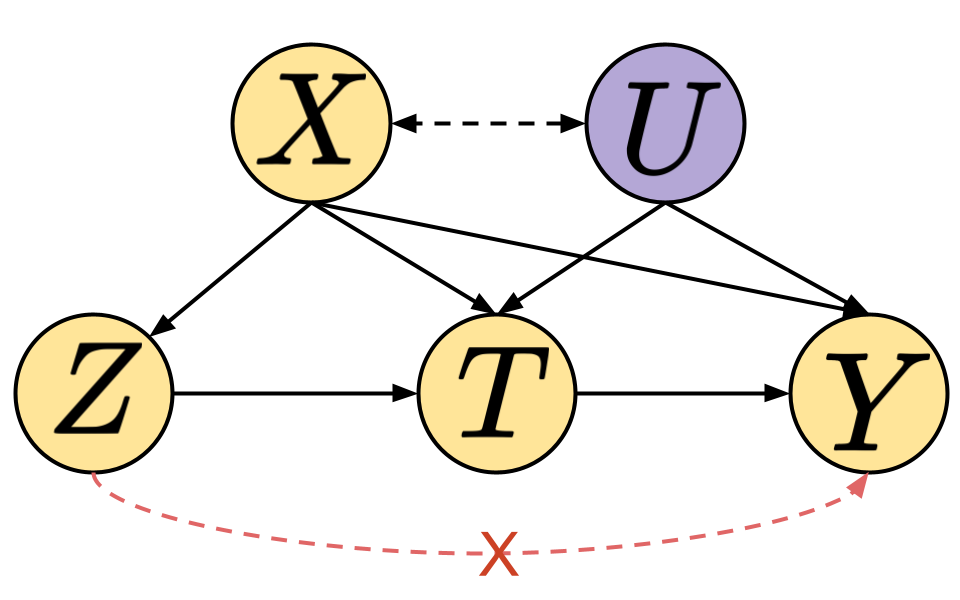
Adaptive Instrument Design for Indirect Experiments
Yash Chandak, Shiv Shankar, Vasilis Syrgkanis, Emma Brunskill.
Twelfth International Conference on Learning Representations (ICLR 2024)
Abstract | Arxiv | Code
Indirect experiments provide a valuable framework for estimating treatment effects in situations where conducting randomized control trials (RCTs) is impractical or unethical. Unlike RCTs, indirect experiments estimate treatment effects by leveraging (conditional) instrumental variables, enabling estimation through encouragement and recommendation rather than strict treatment assignment. However, the sample efficiency of such estimators depends not only on the inherent variability in outcomes but also on the varying compliance levels of users with the instrumental variables and the choice of estimator being used, especially when dealing with numerous instrumental variables. While adaptive experiment design has a rich literature for \textit{direct} experiments, in this paper we take the initial steps towards enhancing sample efficiency for \textit{indirect} experiments by adaptively designing a data collection policy over instrumental variables. Our main contribution is a practical computational procedure that utilizes influence functions to search for an optimal data collection policy, minimizing the mean-squared error of the desired (non-linear) estimator. Through experiments conducted in various domains inspired by real-world applications, we showcase how our method can significantly improve the sample efficiency of indirect experiments.
|
|
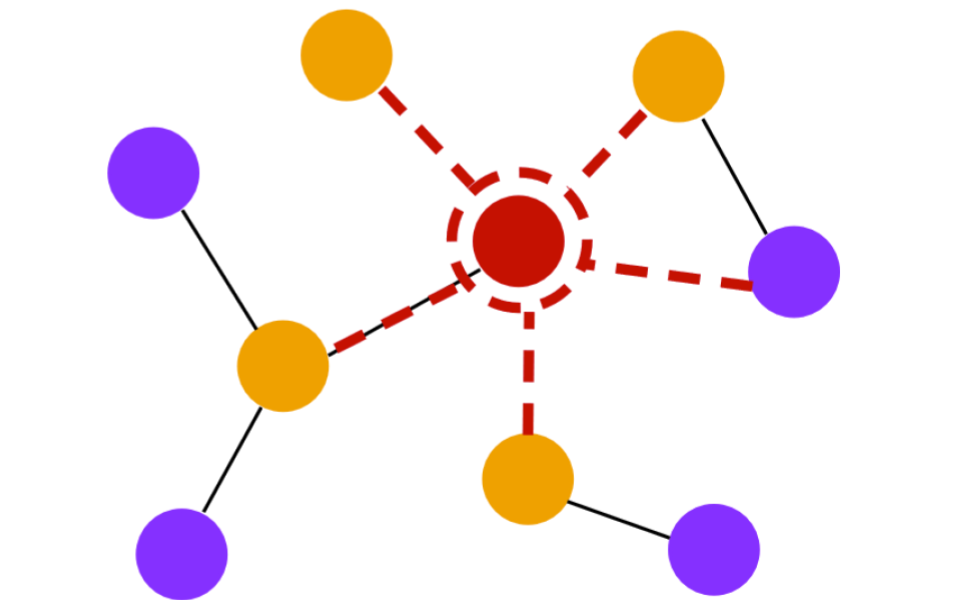
A/B testing under Interference with Partial Network Information
Shiv Shankar, Ritwik Sinha,
Yash Chandak,
Saayan Mitra, Madalina Fiterau.
International Conference on Artificial Intelligence and Statistics (AISTATS 2024)
Abstract | Arxiv
A/B tests are often required to be conducted on subjects that might have social connections. For e.g., experiments on social media, or medical and social interventions to control the spread of an epidemic. In such settings, the SUTVA assumption for randomized-controlled trials is violated due to network interference, or spill-over effects, as treatments to group A can potentially also affect the control group B. When the underlying social network is known exactly, prior works have demonstrated how to conduct A/B tests adequately to estimate the global average treatment effect (GATE). However, in practice, it is often impossible to obtain knowledge about the exact underlying network. In this paper, we present estimator(s)
that relax this assumption and can identify GATE while only relying on knowledge of the superset of neighbors for any subject in the graph. Through theoretical analysis and extensive experiments, we show that the proposed approach performs better in comparison to standard estimators.
|
|
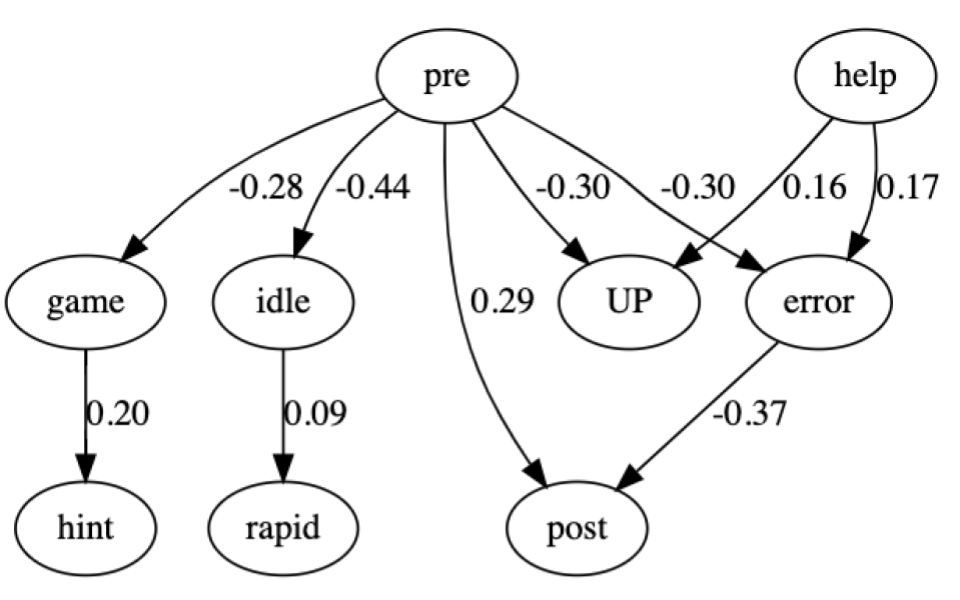
Estimating the Causal Treatment Effect of Unproductive Persistence
Amelia Leon, Allen Nie,
Yash Chandak, Emma Brunskill.
International Conference on Learning Analytics and Knowledge (LAK 2024)
Abstract | Paper
There has been considerable work in classifying and predicting unproductive persistence, but much less in understanding its causal impact on downstream outcomes of interest, like external assessments.
In general, it is experimentally challenging to understand the causal impact because,
unlike in many other settings, we cannot directly intervene (to conduct a randomized control trial)
and cause students to struggle unproductively in an authentic manner. In this work,
we use data from a prior study that used virtual reality headsets to alert teacher's
attention to students who were unproductively struggling. We show that we can use
this as an instrumental variable, and use a two-stage least squares analysis
to provide a causal estimate of the treatment effect of unproductive persistence on
post-test performance. Our results further strengthen the importance of unproductive struggle and highlight the potential of leveraging instruments to identify causal treatment effects of student behaviors during the use of educational technology.
|
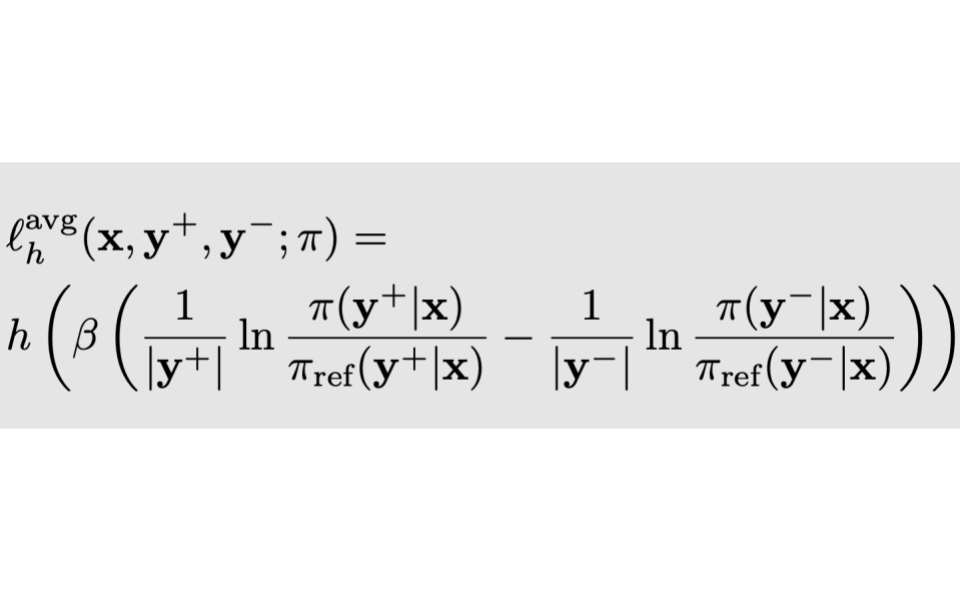
|
Averaging log-likelihoods in direct alignment
Nathan Grinsztajn, Yannis Flet-Berliac, Mohammad Gheshlaghi Azar, Florian Strub, Bill Wu, Eugene Choi, Chris Cremer, Arash Ahmadian, Yash Chandak, Olivier Pietquin, Matthieu Geist
Preprint
Abstract | Arxiv
To better align Large Language Models (LLMs) with human judgment, Reinforcement Learning from Human Feedback (RLHF) learns a reward model and then optimizes it using regularized RL. Recently, direct alignment methods were introduced to learn such a fine-tuned model directly from a preference dataset without computing a proxy reward function. These methods are built upon contrastive losses involving the log-likelihood of (dis)preferred completions according to the trained model. However, completions have various lengths, and the log-likelihood is not length-invariant. On the other side, the cross-entropy loss used in supervised training is length-invariant, as batches are typically averaged token-wise. To reconcile these approaches, we introduce a principled approach for making direct alignment length-invariant. Formally, we introduce a new averaging operator, to be composed with the optimality operator giving the best policy for the underlying RL problem. It translates into averaging the log-likelihood within the loss. We empirically study the effect of such averaging, observing a trade-off between the length of generations and their scores.
|
|
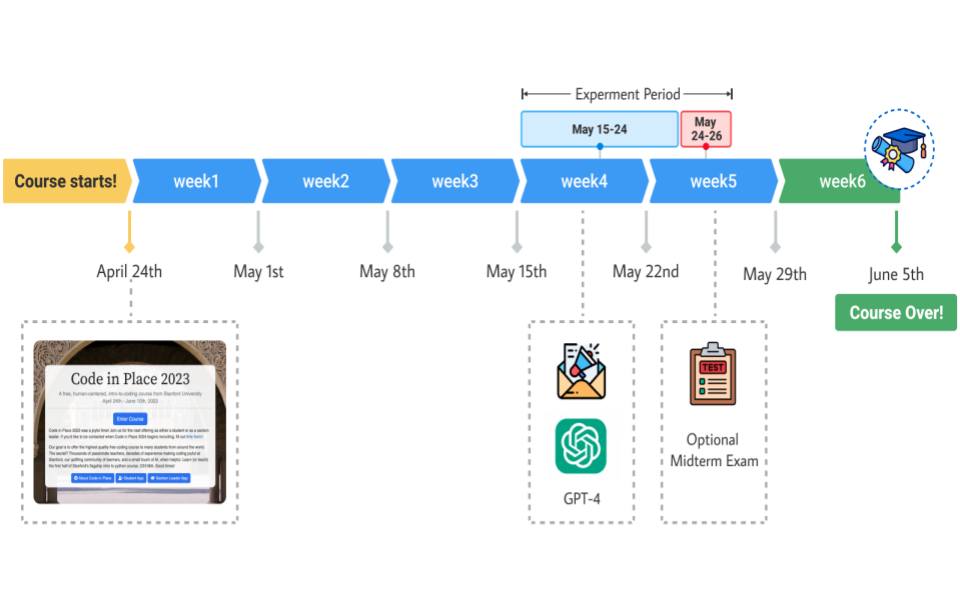
The GPT Surprise: Offering Large Language Model Chat in a Massive Coding Class Reduced Engagement but Increased Adopters’ Exam Performances
Allen Nie, Yash Chandak , Miroslav Suzara, Ali Malik, Juliette Woodrow, Matt Peng, Mehran Sahami, Emma Brunskill, Chris Piech
Preprint
Abstract | Arxiv
Large language models (LLMs) are quickly being adopted in a wide range of learning experiences, especially via ubiquitous and broadly accessible chat interfaces like ChatGPT and Copilot. This type of
interface is readily available to students and teachers around the world, yet relatively little research has
been done to assess the impact of such generic tools on student learning. Coding education is an interesting test case, both because LLMs have strong performance on coding tasks, and because LLM-powered
support tools are rapidly becoming part of the workflow of professional software engineers. To help
understand the impact of generic LLM use on coding education, we conducted a large-scale randomized
control trial with 5,831 students from 146 countries in an online coding class in which we provided some
students with access to a chat interface with GPT-4. We estimate positive benefits on exam performance
for adopters, the students who used the tool, but over all students, the advertisement of GPT-4 led to a
significant average decrease in exam participation. We observe similar decreases in other forms of course
engagement. However, this decrease is modulated by the student’s country of origin. Offering access to
LLMs to students from low human development index countries increased their exam participation rate
on average. Our results suggest there may be promising benefits to using LLMs in an introductory coding
class, but also potential harms for engagement, which makes their longer term impact on student success
unclear. Our work highlights the need for additional investigations to help understand the potential
impact of future adoption and integration of LLMs into classrooms.
|
|
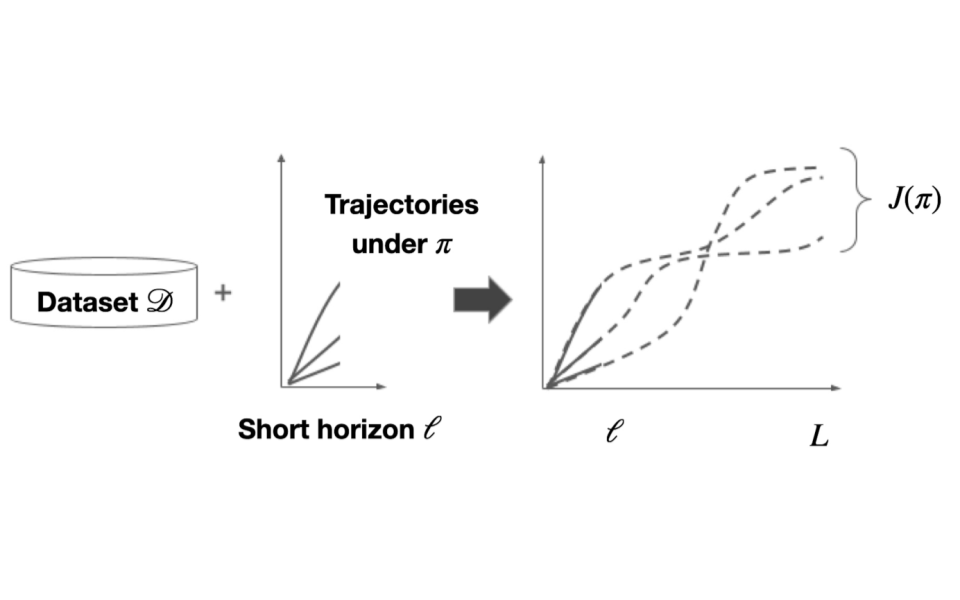
Short-Long Policy Evaluation with Novel Actions
Hyunji Alex Nam, Yash Chandak, Emma Brunskill
Preprint
Abstract | Arxiv
From incorporating LLMs in education, to identifying new drugs and improving ways to charge batteries, innovators constantly try new strategies in search of better long-term outcomes for students, patients and consumers. One major bottleneck in this innovation cycle is the amount of time it takes to observe the downstream effects of a decision policy that incorporates new interventions. The key question is whether we can quickly evaluate long-term outcomes of a new decision policy without making long-term observations. Organizations often have access to prior data about past decision policies and their outcomes, evaluated over the full horizon of interest. Motivated by this, we introduce a new setting for short-long policy evaluation for sequential decision making tasks. Our proposed methods significantly outperform prior results on simulators of HIV treatment, kidney dialysis and battery charging. We also demonstrate that our methods can be useful for applications in AI safety by quickly identifying when a new decision policy is likely to have substantially lower performance than past policies.
|
|
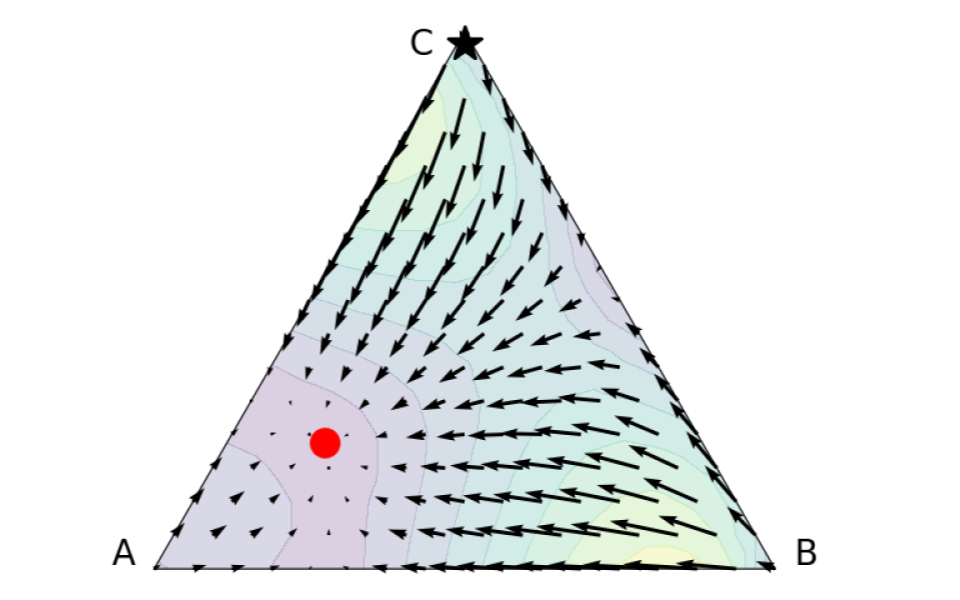
Behavior Alignment via Reward Function Optimization
Dhawal Gupta*,
Yash Chandak*,
Scott Jordan,
Philip Thomas,
Bruno Castro da Silva.
*Equal contribution
(Spotlight) Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS 2023)
Abstract | Arxiv
Designing reward functions to guide reinforcement learning (RL) agents towards desired behavior poses a significant challenge. The difficulty lies in finding the exact reward specification that elicits the desired behavior, as it often leads to sparse learning feedback for the agent. Modifying the reward specification to provide dense feedback may introduce unintended consequences and encourage undesirable behavior. While potential-based reward shaping has been proposed as a solution, we demonstrate its limitations in resolving sub-optimalities resulting from various design choices, and its potential to significantly degrade performance when used naively. To overcome these challenges, we propose a novel framework that employs a bi-level objective for learning a ``behavior alignment reward''. This reward function combines auxiliary rewards, defined by a designer's heuristics, with primary rewards provided by the environment. By doing so, our method remains robust against heuristic misspecification and dynamically adapts the agent's policy optimization procedure, addressing other sub-optimalities introduced by algorithmic design choices. We validate the effectiveness of our approach across a range of tasks, from small-scale to high-dimensional control tasks, where we incorporate heuristics of varying quality as auxiliary rewards, some of which are beneficial and others detrimental. Our framework offers a robust approach for incorporating heuristics that surpasses the limitations of previous methods, including potential-based reward shaping.
|
|
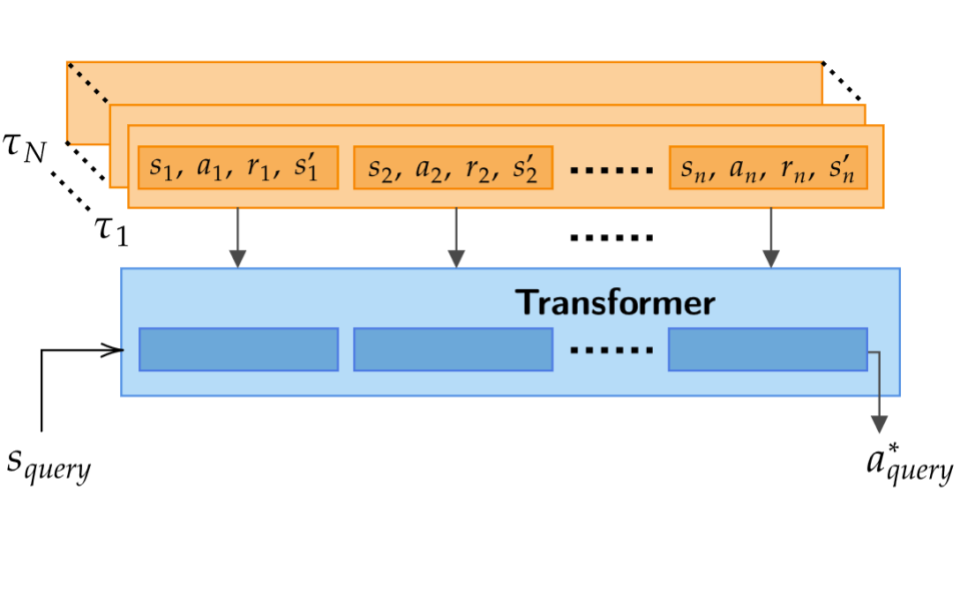
Supervised Pretraining Can Learn In-Context Reinforcement Learning
Jonathan N. Lee,
Annie Xie,
Aldo Pacchiano,
Yash Chandak,
Chelsea Finn,
Ofir Nachum,
Emma Brunskill.
(Spotlight) Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS 2023)
New Frontiers in Learning, Control, and Dynamical Systems Workshop (ICML 2023)
Abstract | Arxiv
Large transformer models trained on diverse datasets have shown a remarkable ability to learn in-context, achieving high few-shot performance on tasks they were not explicitly trained to solve. In this paper, we study the in-context learning capabilities of transformers in decision-making problems, i.e., reinforcement learning (RL) for bandits and Markov decision processes. To do so, we introduce and study Decision-Pretrained Transformer (DPT), a supervised pretraining method where the transformer predicts an optimal action given a query state and an in-context dataset of interactions, across a diverse set of tasks. This procedure, while simple, produces a model with several surprising capabilities. We find that the pretrained transformer can be used to solve a range of RL problems in-context, exhibiting both exploration online and conservatism offline, despite not being explicitly trained to do so. The model also generalizes beyond the pretraining distribution to new tasks and automatically adapts its decision-making strategies to unknown structure. Theoretically, we show DPT can be viewed as an efficient implementation of Bayesian posterior sampling, a provably sample-efficient RL algorithm. We further leverage this connection to provide guarantees on the regret of the in-context algorithm yielded by DPT, and prove that it can learn faster than algorithms used to generate the pretraining data. These results suggest a promising yet simple path towards instilling strong in-context decision-making abilities in transformers.
|

|
Representations and Exploration for Deep Reinforcement Learning using Singular Value Decomposition
Yash Chandak,
Shantanu Thakoor,
Zhaohan Daniel Guo,
Yunhao Tang,
Remi Munos,
Will Dabney,
Diana Borsa.
40th International Conference on Machine Learning (ICML 2023)
Abstract | Arxiv
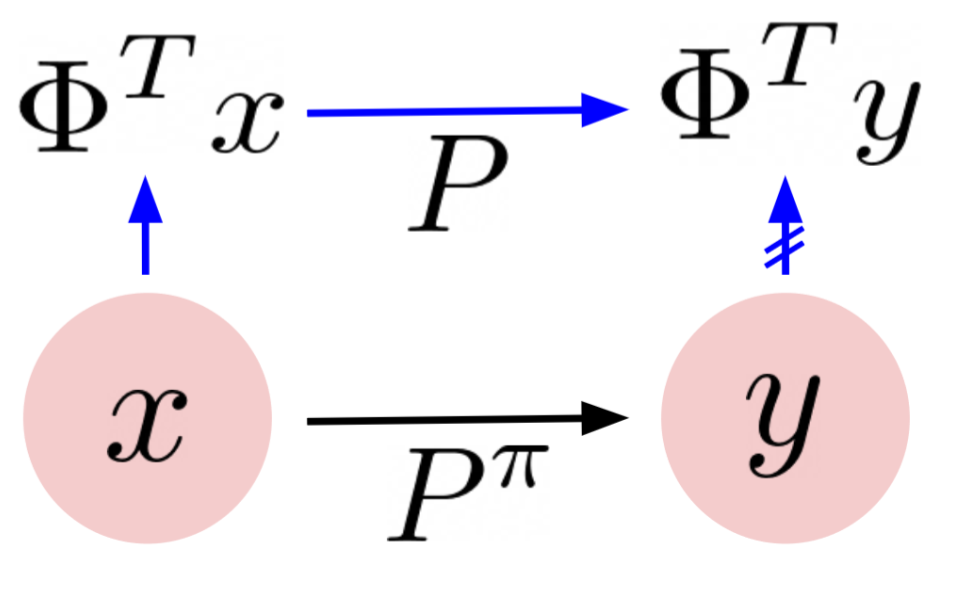
Representation learning and exploration are among the key challenges for any deep reinforcement learning agent. In this work, we provide a singular value decomposition based method that can be used to obtain representations that preserve the underlying transition structure in the domain. Perhaps interestingly, we show that these representations also capture the relative frequency of state visitations, thereby providing an estimate for pseudo-counts for free. To scale this decomposition method to large-scale domains, we provide an algorithm that never requires building the transition matrix, can make use of deep networks, and also permits mini-batch training. Further, we draw inspiration from predictive state representations and extend our decomposition method to partially observable environments. With experiments on multi-task settings with partially observable domains, we show that the proposed method can not only learn useful representation on DM-Lab-30 environments (that have inputs involving language instructions, pixel images, rewards, among others) but it can also be effective at hard exploration tasks in DM-Hard-8 environments.
|
|
Understanding Self-Predictive Learning for Reinforcement Learning
Yunhao Tang,
Zhaohan Daniel Guo,
Pierre Harvey Richemond ,
Bernardo ́Avila Pires,
Yash Chandak,
Remi Munos,
Mark Rowland,
Mohammad Gheshlaghi Azar,
Charline Le Lan,
Clare Lyle,
Andras Gyorgy,
Shantanu Thakoor,
Will Dabney,
Bilal Piot,
Daniele Calandriello,
Michal Valko
40th International Conference on Machine Learning (ICML 2023)
Abstract | Arxiv
We study the learning dynamics of self-predictive learning for reinforcement learning, a family of algorithms that learn representations by minimizing the prediction error of their own future latent representations.
Despite its recent empirical success, such algorithms have an apparent defect: trivial representations (such as constants) minimize the prediction error, yet it is obviously undesirable to converge to such solutions.
%\berna{Not only undesirable, but rarely observed in practice.}
Our central insight is that careful designs of the optimization dynamics are critical to learning meaningful representations. We identify that a faster paced optimization of the predictor and semi-gradient updates on the representation, are crucial to preventing the representation collapse. Then in an idealized setup, we show self-predictive learning dynamics carries out spectral decomposition on the state transition matrix, effectively capturing information of the transition dynamics. Building on the theoretical insights, we propose bidirectional self-predictive learning, a novel self-predictive algorithm that learns two representations simultaneously. We examine the robustness of our theoretical insights with a number of small-scale experiments and showcase the promise of the novel representation learning algorithm with large-scale experiments.
|

|
Asymptotically Unbiased Off-Policy Policy Evaluation when Reusing Old Data
in Nonstationary Environments
Vincent Liu,
Yash Chandak,
Philip Thomas,
Martha White
26th International Conference on Artificial Intelligence and Statistics (AISTATS 2023)
Abstract | Arxiv
Reinforcement learning (RL) has emerged as a general-purpose technique for
addressing problemIn this work, we consider the off-policy policy evaluation problem for contextual bandits and finite horizon reinforcement learning in the nonstationary setting. Reusing old data is critical for policy evaluation, but existing estimators that reuse old data introduce large bias such that we can not obtain a valid confidence interval. Inspired from a related field called survey sampling, we introduce a variant of the doubly robust (DR) estimator, called the regression-assisted DR estimator, that can incorporate the past data without introducing a large bias. The estimator unifies several existing off-policy policy evaluation methods and improves on them with the use of auxiliary information and a regression approach. We prove that the new estimator is asymptotically unbiased, and provide a consistent variance estimator to a construct a large sample confidence interval. Finally, we empirically show that the new estimator improves estimation for the current and future policy values, and provides a tight and valid interval estimation in several nonstationary recommendation environments.
|
|
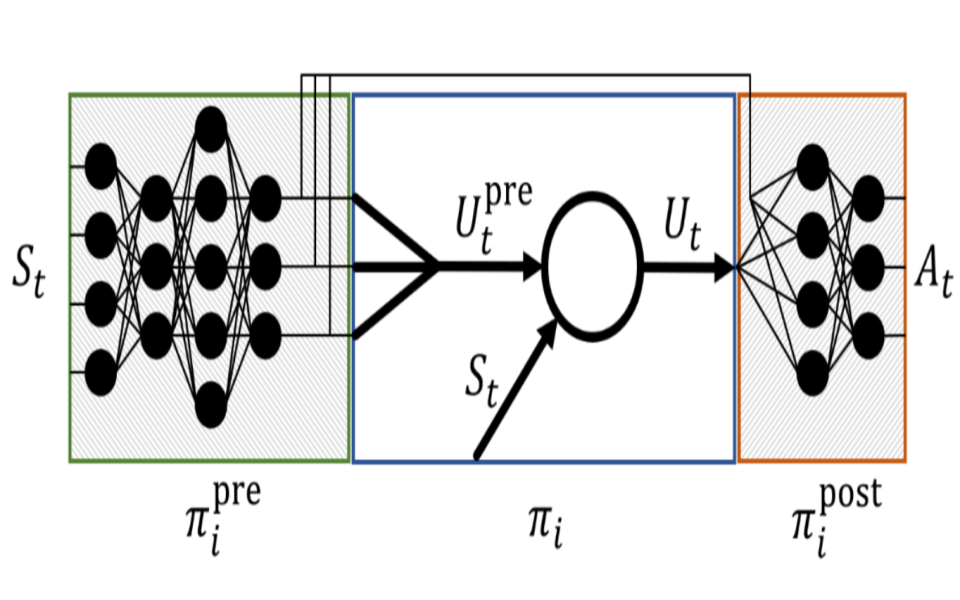
Coagent Networks: Generalized and Scaled
James E Kostas, Scott M Jordan, Yash Chandak, Georgios Theocharous, Dhawal Gupta, Martha White, Bruno Castro da Silva, Philip S Thomas
Preprint
Abstract | Arxiv
Coagent networks for reinforcement learning (RL) [Thomas and Barto, 2011]
provide a powerful and flexible framework for deriving principled learning rules
for arbitrary stochastic neural networks. The coagent framework offers an alternative to backpropagation-based deep learning (BDL) that overcomes some of
backpropagation’s main limitations. For example, coagent networks can compute
different parts of the network asynchronously (at different rates or at different
times), can incorporate non-differentiable components that cannot be used with
backpropagation, and can explore at levels higher than their action spaces (that
is, they can be designed as hierarchical networks for exploration and/or temporal
abstraction). However, the coagent framework is not just an alternative to BDL;
the two approaches can be blended: BDL can be combined with coagent learning
rules to create architectures with the advantages of both approaches. This work
generalizes the coagent theory and learning rules provided by previous works; this
generalization provides more flexibility for network architecture design within
the coagent framework. This work also studies one of the chief disadvantages of
coagent networks: high variance updates for networks that have many coagents
and do not use backpropagation. We show that a coagent algorithm with a policy
network that does not use backpropagation can scale to a challenging RL domain
with a high-dimensional state and action space (the MuJoCo Ant environment),
learning reasonable (although not state-of-the-art) policies. These contributions
motivate and provide a more general theoretical foundation for future work that
studies coagent networks
|
|
Reinforcement Learning for Non-stationary Problems
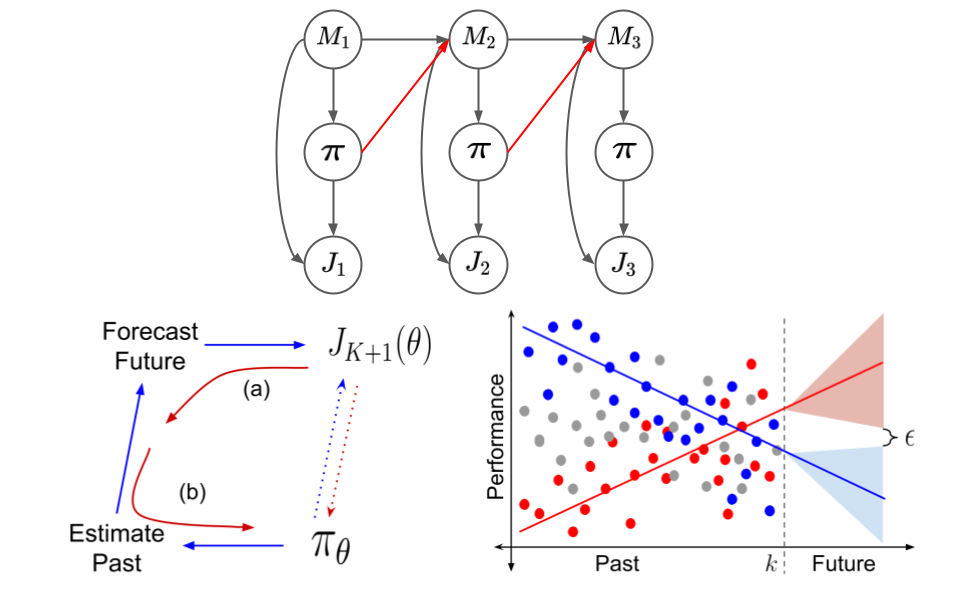
Yash Chandak
PhD Thesis, School of Computer Science, University of Massachusetts, September 2022.
Abstract | Pdf
Reinforcement learning (RL) has emerged as a general-purpose technique for
addressing problems involving sequential decision-making. However, most RL methods
are based upon the fundamental assumption that the transition dynamics and reward
functions are fixed, that is, the underlying Markov decision process is stationary.
This limits the applicability of such RL methods because real-world problems are
often subject to changes due to external factors (passive non-stationarity), or changes
induced by interactions with the system itself (active non-stationarity), or both
(hybrid non-stationarity). For example, personalized automated healthcare systems
and other automated human-computer interaction systems need to constantly account
for changes in human behavior and interests that occur over time. Further, when the
stakes associated with financial risks or human life are high, the cost associated with a false stationarity assumption may be unacceptable. In this work, we address several
challenges underlying (off-policy) policy evaluation, improvement, and safety amidst
such non-stationarities. Our approach merges ideas from reinforcement learning,
counterfactual reasoning, and time-series analysis.
When the stationarity assumption is violated, using existing algorithms may result
in a performance lag and false safety guarantees. This raises the question: how can we
use historical data to optimize for future scenarios? To address this challenges in the
presence of passive non-stationarity, we show how future performance of a policy can
be evaluated using a forecast obtained by fitting a curve to counter-factual estimates
of policy performances over time, without ever directly modeling the underlying
non-stationarity. We show that this approach further enables policy improvement to
proactively search for a good future policy by leveraging a policy gradient algorithm
that maximizes a forecast of future performance. Building upon these advances, we
present a Seldonian algorithm that provides the first steps towards ensuring safety,
with high confidence, for smoothly-varying non-stationary decision problems.
The presence of active and hybrid non-stationarity pose additional challenges by
exposing a completely new feedback loop that allows an agent to potentially control
the non-stationary aspects of the environment. This makes the outcomes of future
decisions dependent on all of the past interactions, thereby resulting in effectively a
single lifelong sequence of decisions. We propose a method that provides the first steps
towards a general procedure for on-policy and off-policy evaluation amidst structured
changes due to active, passive, or hybrid non-stationarity.
|
|
Off-Policy Evaluation for Action-Dependent Non-stationary Environments
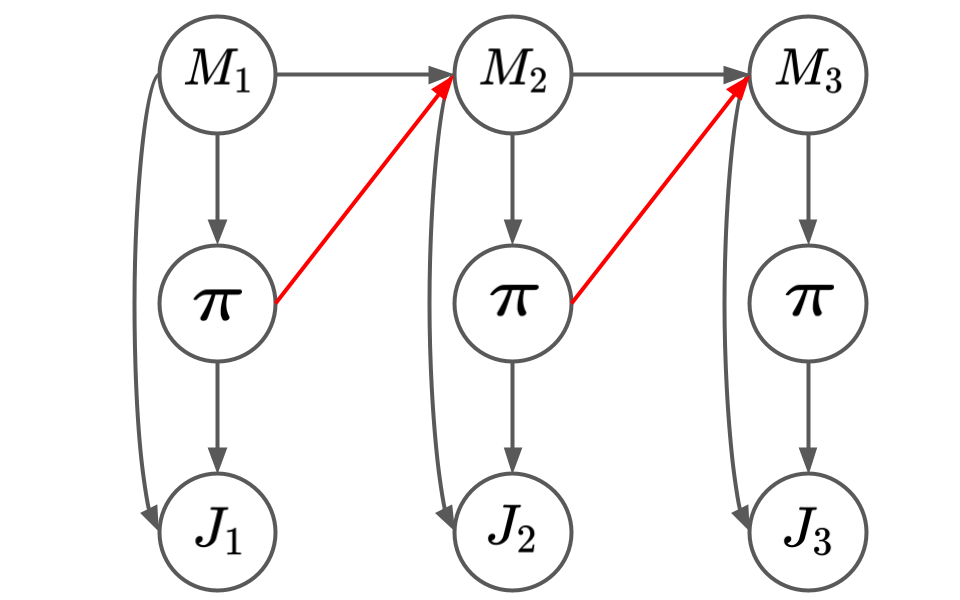
Yash Chandak,
Shiv Shankar,
Nathaniel D. Bastian,
Bruno Castro da Silva,
Emma Brunskill,
Philip Thomas
Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS 2022)
Abstract | Arxiv | Code | Video
Methods for sequential decision-making are often built upon a foundational assumption that the underlying decision process is stationary. This limits the application of such methods because real-world problems are often subject to changes due to external factors (\textit{passive} non-stationarity), changes induced by interactions with the system itself (\textit{active} non-stationarity), or both (\textit{hybrid} non-stationarity). In this work, we take the first steps towards the fundamental challenge of on-policy and off-policy evaluation amidst structured changes due to active, passive, or hybrid non-stationarity. Towards this goal, we make a \textit{higher-order stationarity} assumption such that non-stationarity results in changes over time, but the way changes happen is fixed. We propose, OPEN, an algorithm that uses a double application of counterfactual reasoning and a novel importance-weighted instrument-variable regression to obtain both a lower bias and a lower variance estimate of the structure in the changes of a policy's past performances. Finally, we show promising results on how OPEN can be used to predict future performances for several domains inspired by real-world applications that exhibit non-stationarity.
|
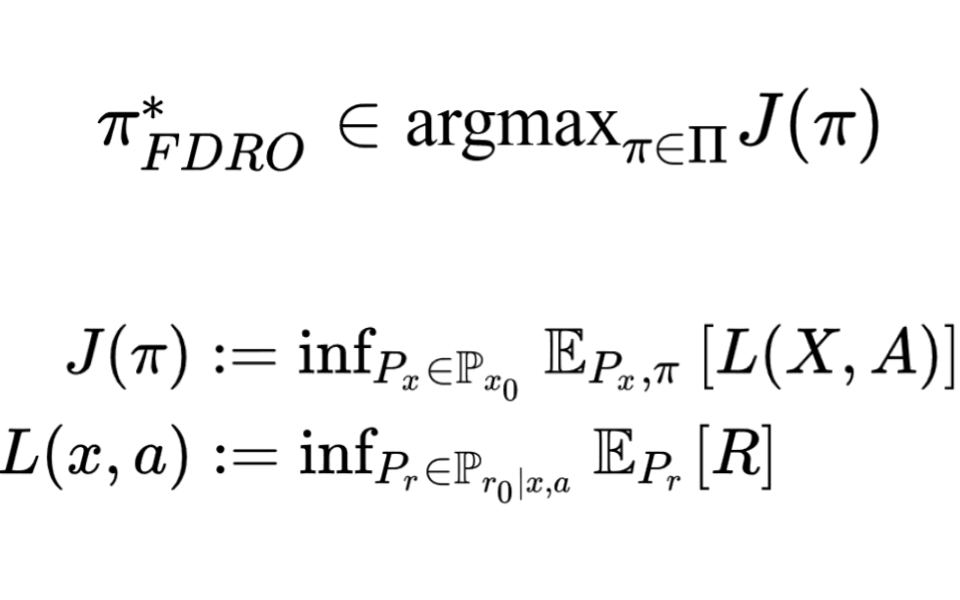
|
Factored DRO: Factored Distributionally Robust Policies for Contextual Bandits
Tong Mu,
Yash Chandak,
Tatsunori Hashimoto,
Emma Brunskill
Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS 2022)
Abstract | Paper
While there has been extensive work on learning from offline data for contextual multi-armed bandit settings, existing methods typically assume there is no environment shift: that the learned policy will operate in the same environmental process as that of data collection. However, this assumption may overly limit the use of these methods for many practical situations where there may be distribution shifts. In this work we propose Factored Distributionally Robust Optimization (Factored-DRO), which is able to separately handle distribution shifts in the context distribution and shifts in the reward generating process. Prior work that either ignores potential shifts in the context, or considers them jointly, can lead to performance that is too conservative and does not consider context shift at all, especially under certain forms of reward feedback. Our Factored-DRO objective mitigates this by considering the shifts separately, and our proposed estimators are consistent and converge asymptotically. We also introduce a practical algorithm and demonstrate promising empirical results in environments based on real-world datasets, such as voting outcomes and scene classification.
|
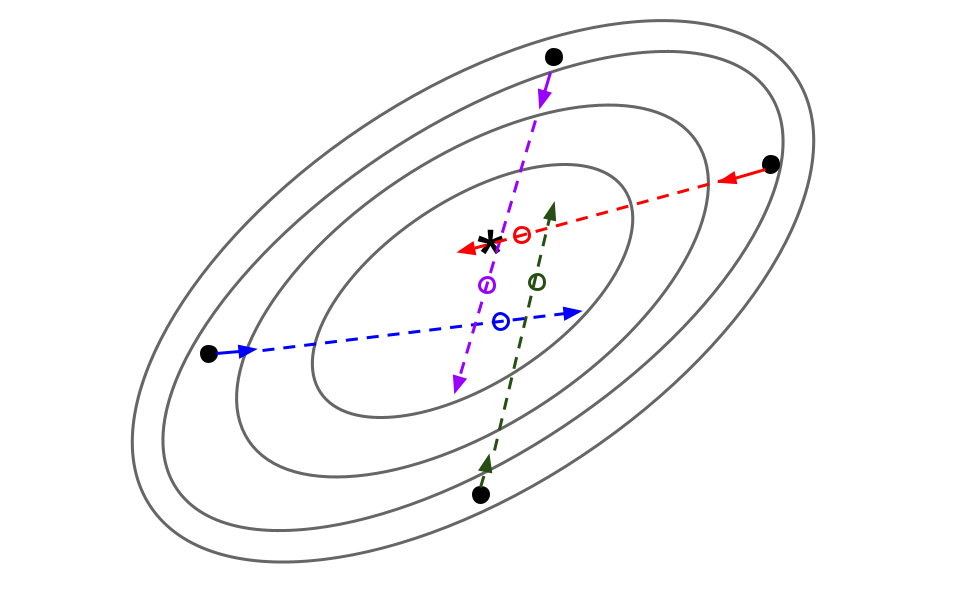
|
Optimization using Parallel Gradient Evaluations on Multiple Parameters
Yash Chandak,
Shiv Shankar,
Venkata Gandikota,
Philip Thomas,
Arya Mazumdar
OPT workshop @ Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS 2022)
Abstract | Arxiv
We propose a first-order method for convex optimization, where instead of being restricted to the gradient from a single parameter, gradients from multiple parameters can be used during each step of gradient descent. This setup is particularly useful when a few processors are available that can be used in parallel for optimization. Our method uses gradients from multiple parameters in synergy to update these parameters together towards the optima. While doing so, it is ensured that the computational and memory complexity is of the same order as that of gradient descent. Empirical results demonstrate that even using gradients from as low as \textit{two} parameters, our method can often obtain significant acceleration and provide robustness to hyper-parameter settings. We remark that the primary goal of this work is less theoretical, and is instead aimed at exploring the understudied case of using multiple gradients during each step of optimization.
|
|
|
A Generalized Learning Rule for Asynchronous Coagent Networks
James Kostas,
Scott Jordan,
Yash Chandak,
Georgios Theocharous,
Dhawal Gupta,
Philip Thomas
5th Multidisciplinary Conference on Reinforcement Learning and Decision Making (RLDM 2022)
Abstract
Coagent networks for reinforcement learning (RL) (Thomas and Barto, 2011) provide a framework for deriving principled learning rules for stochastic neural networks in the RL setting. Previous work provided generalized coagent learning rules for the asynchronous setting (Kostas et al., 2020) and for the setting in which network parameters are shared (Zini et al., 2020). This work provides a generalized theorem that can be used to obtain learning rules for the combination of those cases; that is, the case where an asynchronous coagent network uses shared parameters. This work also provides a discussion of recent, ongoing, and future work.
|
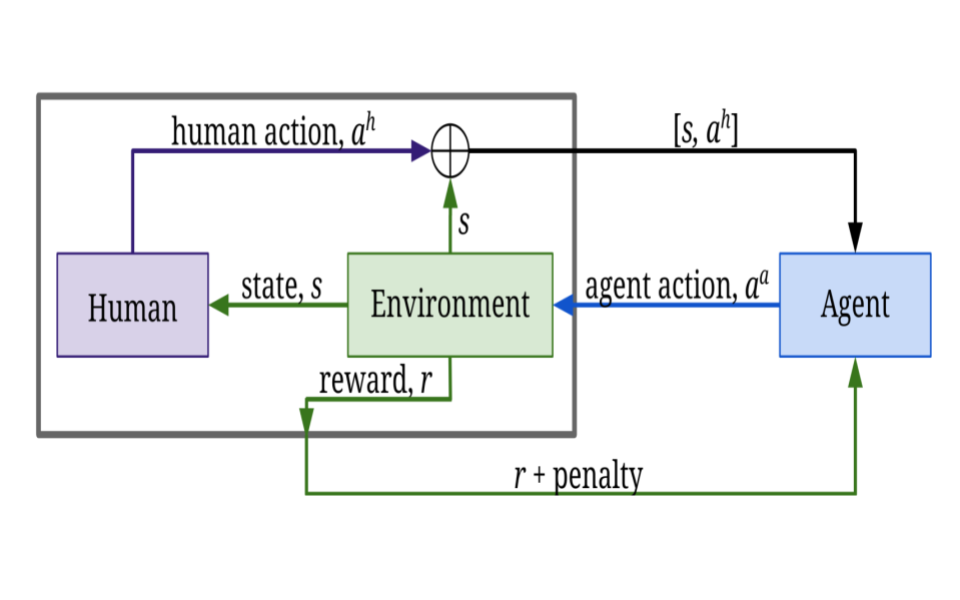
|
On Optimizing Interventions in Shared Autonomy
Weihao Tan*,
David Koleczek*,
Siddhant Pradhan*,
Nicholas Perello,
Vivek Chettiar,
Nan Ma,
Aaslesha Rajaram,
Vishal Rohra,
Soundar Srinivasan,
H M Sajjad Hossain^,
Yash Chandak^
*Equal contribution, ^Equal advising
Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI 2022)
Abstract | Arxiv
Shared autonomy refers to approaches for enabling an autonomous agent to collaborate with a human with the aim of improving human performance. However, besides improving performance, it may often also be beneficial that the agent concurrently accounts for preserving the user’s experience or satisfaction of collaboration. In order to address this additional goal, we examine approaches for improving the user experience by constraining the number of interventions by the autonomous agent. We propose two model-free reinforcement learning methods that can account for both hard and soft constraints on the number of interventions. We show that not only does our method outperform the existing baseline, but also eliminates the need to manually tune a black-box hyperparameter for controlling the level of assistance. We also provide an in-depth analysis of intervention scenarios in order to further illuminate system understanding.
|
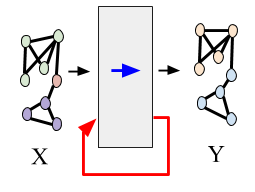
|
Scaling Graph Propagation Kernels for Predictive Learning
Priyesh Vijayan
Yash Chandak,
Mitesh Khapra,
Srinivasan Parthasarathy,
Balaraman Ravindran
Frontiers in Big Data, section Data Mining and Management (Frontiers 2022).
Abstract | Paper | Code
Given a graph where every node has certain attributes associated with it and some nodes have labels associated with them, Collective Classification (CC) is the task of assigning labels to every unlabeled node using information from the node as well as its neighbors. It is often the case that a node is not only influenced by its immediate neighbors but also by higher order neighbors, multiple hops away. Recent state-of-the-art models for CC learn end-to-end differentiable variations of Weisfeiler-Lehman (WL) kernels to aggregate multi-hop neighborhood information. In this work, we propose a Higher Order Propagation Framework, HOPF, which provides an iterative inference mechanism for these powerful differentiable kernels. Such a combination of classical iterative inference mechanism with recent differentiable kernels allows the framework to learn graph convolutional filters that simultaneously exploit the attribute and label information available in the neighborhood. Further, these iterative differentiable kernels can scale to larger hops beyond the memory limitations of existing differentiable kernels. We also show that existing WL kernel-based models suffer from the problem of Node Information Morphing where the information of the node is morphed or overwhelmed by the information of its neighbors when considering multiple hops. To address this, we propose a specific instantiation of HOPF, called the NIP models, which preserves the node information at every propagation step. The iterative formulation of NIP models further helps in incorporating distant hop information concisely as summaries of the inferred labels. We do an extensive evaluation across 11 datasets from different domains. We show that existing CC models do not provide consistent performance across datasets, while the proposed NIP model with iterative inference is more robust.
|
|
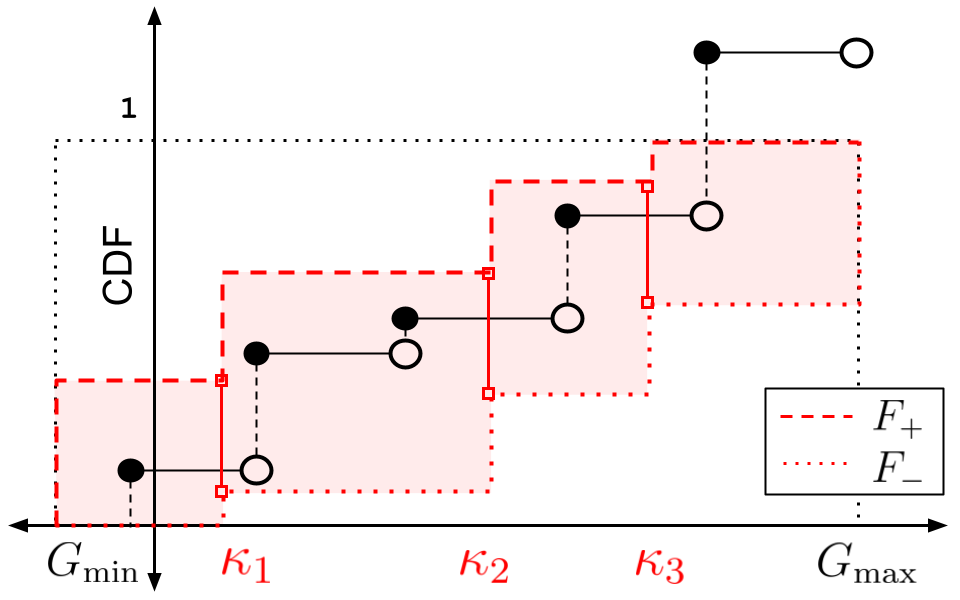
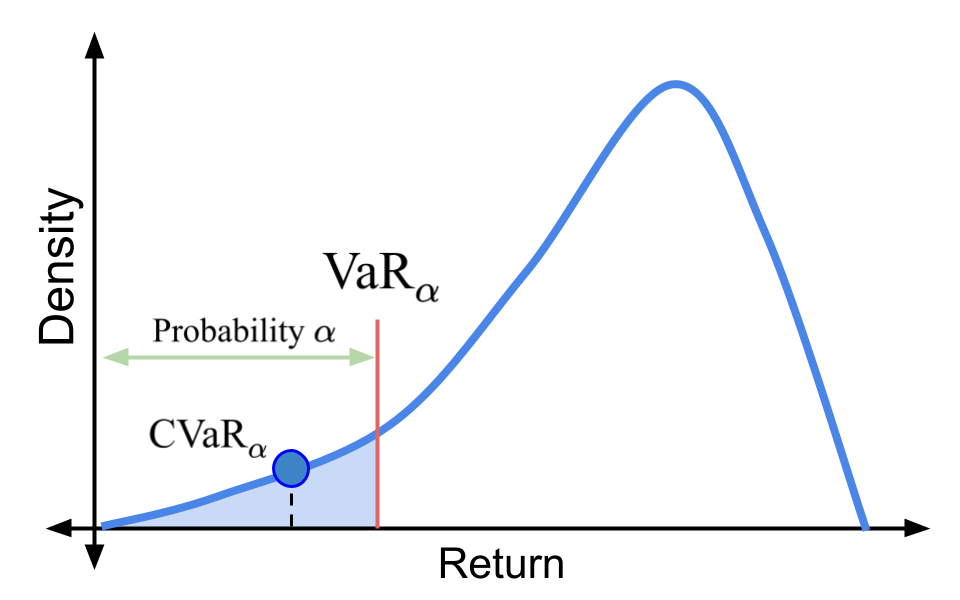
Universal Off-Policy Evaluation
Yash Chandak,
Scott Niekum,
Bruno Castro da Silva,
Erik Learned-Miller,
Emma Brunskill,
Philip Thomas
Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021)
5th Multidisciplinary Conference on Reinforcement Learning and Decision Making (RLDM 2022)
Best Paper Award at RLDM.
Abstract | Arxiv | Code | Video | Tutorial
When faced with sequential decision-making problems, it is often useful to be able to predict what would happen if decisions were made using a new policy. Those predictions must often be based on data collected under some previously used decision-making rule. Many previous methods enable such off-policy (or counterfactual) estimation of the expected value of a performance measure called the return. In this paper, we take the first steps towards a universal off-policy estimator (UnO) -- one that provides off-policy estimates and high-confidence bounds for any parameter of the return distribution. We use UnO for estimating and simultaneously bounding the mean, variance, quantiles/median, inter-quantile range, CVaR, and the entire cumulative distribution of returns. Finally, we also discuss Uno's applicability in various settings, including fully observable, partially observable (i.e., with unobserved confounders), Markovian, non-Markovian, stationary, smoothly non-stationary, and discrete distribution shifts.
|
|
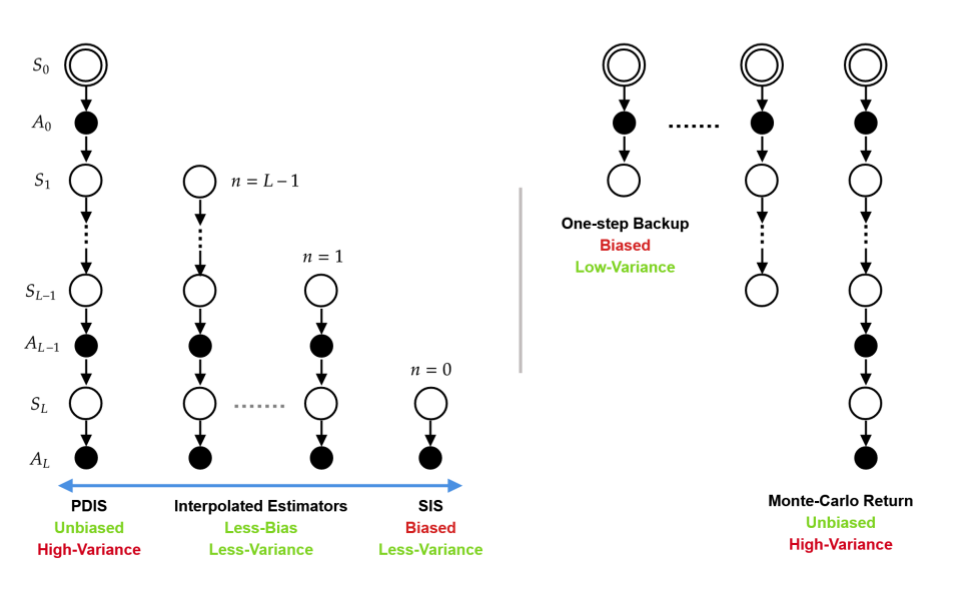
SOPE: Spectrum of Off-Policy Estimators
Christina Yuan,
Yash Chandak,
Stephen Giguere,
Philip Thomas,
Scott Niekum
Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021)
5th Multidisciplinary Conference on Reinforcement Learning and Decision Making (RLDM 2022)
Abstract | Arxiv | Code | Video
Many sequential decision making problems are high-stakes and require off-policy evaluation (OPE) of a new policy using historical data collected using some other policy. One of the most common OPE technique that provides unbiased estimates is trajectory based importance sampling (IS). However, due to the high variance of trajectory IS estimates, importance sampling methods based on stationary distributions (SIS) have recently been adopted. Unfortunately, while SIS often provides lower variance estimates, estimating the stationary distribution ratios can be challenging and lead to biased estimates. In this paper, we present a new perspective on this bias-variance trade-off and show the existence of a spectrum of estimators whose endpoints are SIS and IS, respectively. We then show that estimators in this spectrum allow us to trade-off between the bias and variance of IS and SIS and can achieve lower mean-squared error than both IS and SIS.
|
|
Behavior Policy Search for Risk Estimators in Reinforcement Learning
Elita Lobo,
Yash Chandak,
Dharmashankar Subramanian,
Josiah Hanna,
Marek Petrik
SafeRL workshop @ Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021)
Abstract | pdf
In real-world sequential decision problems, exploration is expensive, and the risk of expert decision policies must be evaluated from limited data. In this setting, Monte Carlo (MC) risk estimators are typically used to estimate the risk of decision policies. While these estimators have the desired low bias property, they often suffer from large variance. In this paper, we consider the problem of minimizing the asymptotic mean squared error and hence variance of MC risk estimators.
We show that by carefully choosing the data sampling policy (\emph{behavior policy}), we can obtain low variance estimates of the risk of any given decision policy.
|
|
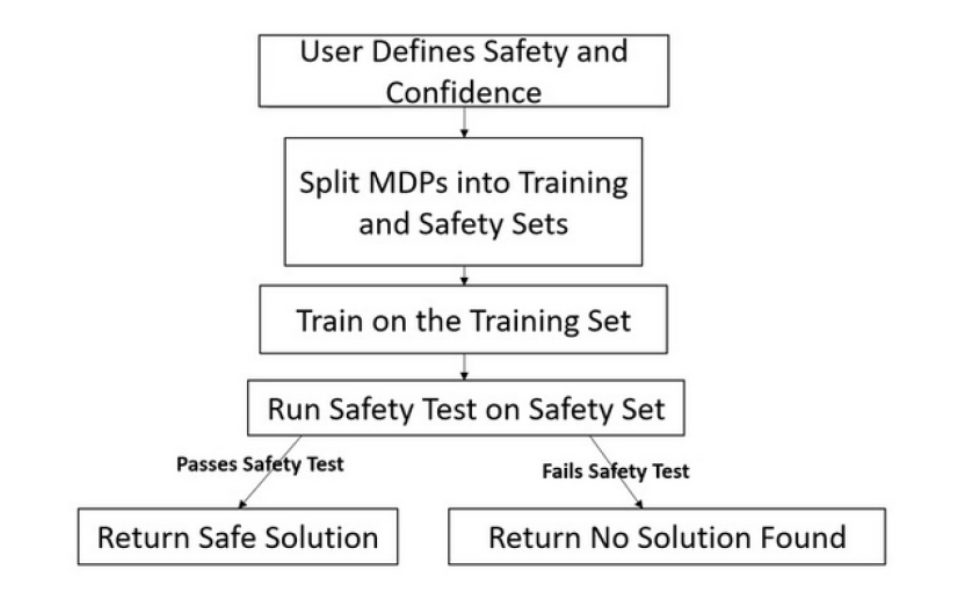
High Confidence Generalization for Reinforcement Learning
James Kostas,
Yash Chandak,
Scott Jordan,
Georgios Theocharous,
Philip Thomas
Thirty-eighth International Conference on Machine Learning (ICML 2021)
Abstract | pdf | Video
We present several classes of reinforcement learn-ing algorithms that safely generalize toMarkovdecision processes(MDPs) not seen during train-ing. Specifically, we study the setting in whichsome set of MDPs is accessible for training. Forvarious definitions of safety, our algorithms giveprobabilistic guarantees that agents can safely gen-eralize to MDPs that are sampled from the samedistribution but are not necessarily in the train-ing set. These algorithms are a type ofSeldo-nianalgorithm (Thomas et al., 2019), which is aclass of machine learning algorithms that returnmodels with probabilistic safety guarantees foruser-specified definitions of safety.
|
|
|
Intervention Aware Shared Autonomy
Weihao Tan*,
David Koleczek*,
Siddhant Pradhan*,
Nicholas Perello,
Vivek Chettiar,
Nan Ma,
Aaslesha Rajaram,
Vishal Rohra,
Soundar Srinivasan,
H M Sajjad Hossain^,
Yash Chandak^.
*Equal contribution, ^Equal advising
HumanAI workshop @ Thirty-eighth International Conference on Machine Learning (ICML 2021)
Abstract | pdf
Shared autonomy refers to approaches for en-abling an autonomous agent to collaborate witha human with the aim of improving human per-formance. However, besides improving perfor-mance, it may often be beneficial that the agentconcurrently accounts for preserving the user’sexperience or satisfaction of collaboration. In or-der to address this additional goal, we examineapproaches for improving the user experience byconstraining the number of interventions by theautonomous agent. We propose two model-freereinforcement learning methods that can accountfor both hard and soft constraints on the numberof interventions. We show that not only does ourmethod outperform the existing baseline, but alsoeliminates the need to manually tune an arbitraryhyperparameter for controlling the level of assis-tance. We also provide an in-depth analysis ofintervention scenarios in order to further illumi-nate system understanding.
|
|
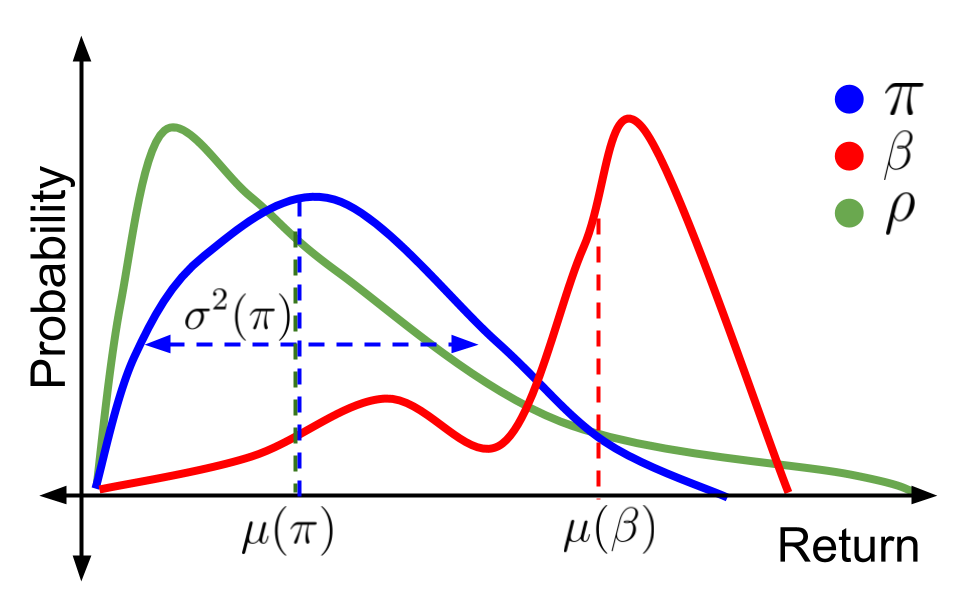
High Confidence Off-Policy (or Counterfactual) Variance Estimation
Yash Chandak,
Shiv Shankar,
Philip Thomas
Thirty-fifth AAAI Conference on Artificial Intelligence (AAAI 2021)
Abstract | Arxiv | Code
Many sequential decision-making systems leverage data collected using prior policies to propose a new policy. In critical applications, it is important that high-confidence guarantees on the new policy's behavior are provided before deployment, to ensure that the policy will behave as desired. Prior works have studied high-confidence off-policy estimation of the \emph{expected} return, however, high-confidence off-policy estimation of the \emph{variance} of returns can be equally critical for high-risk applications. In this paper, we tackle the previously open problem of estimating and bounding, with high confidence, the variance of returns from off-policy data.
|
|
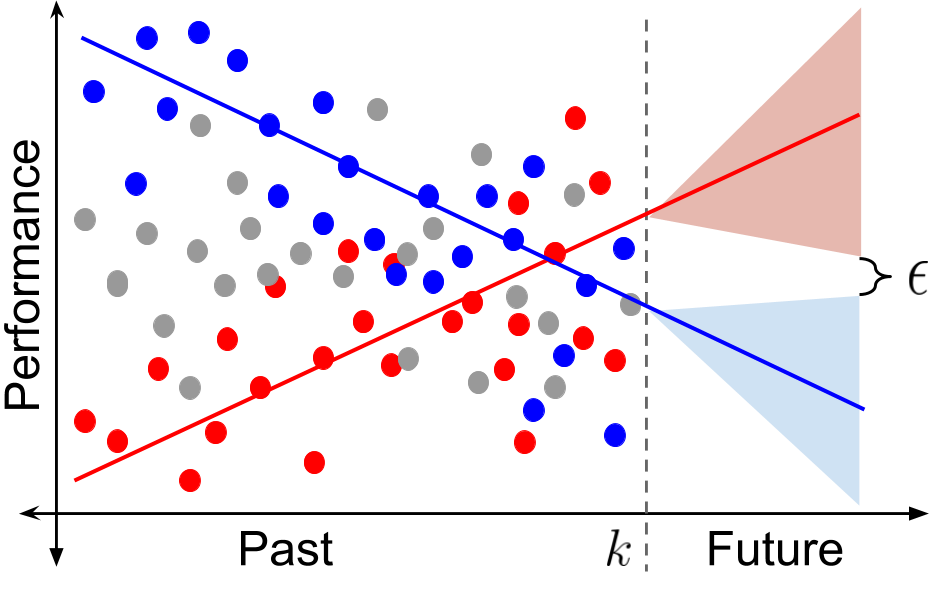
Towards Safe Policy Improvement for Non-Stationary MDPs
Yash Chandak,
Scott Jordan,
Georgios Theocharous,
Martha White,
Philip Thomas
(Spotlight) Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS 2020)
Abstract | Arxiv | Blogpost | Code | Video
Many real-world sequential decision-making problems involve critical systems that present both human-life and financial risks. While several works in the past have proposed methods that are safe for deployment, they assume that the underlying problem is stationary. However, many real-world problems of interest exhibit non-stationarity, and when stakes are high, the cost associated with a false stationarity assumption may be unacceptable. Addressing safety in the presence of non-stationarity remains an open question in the literature. We present a type of Seldonian algorithm (Thomas et al., 2019), taking the first steps towards ensuring safety, with high confidence, for smoothly varying non-stationary decision problems, through a synthesis of model-free reinforcement learning algorithms with methods from time-series analysis.
|
|
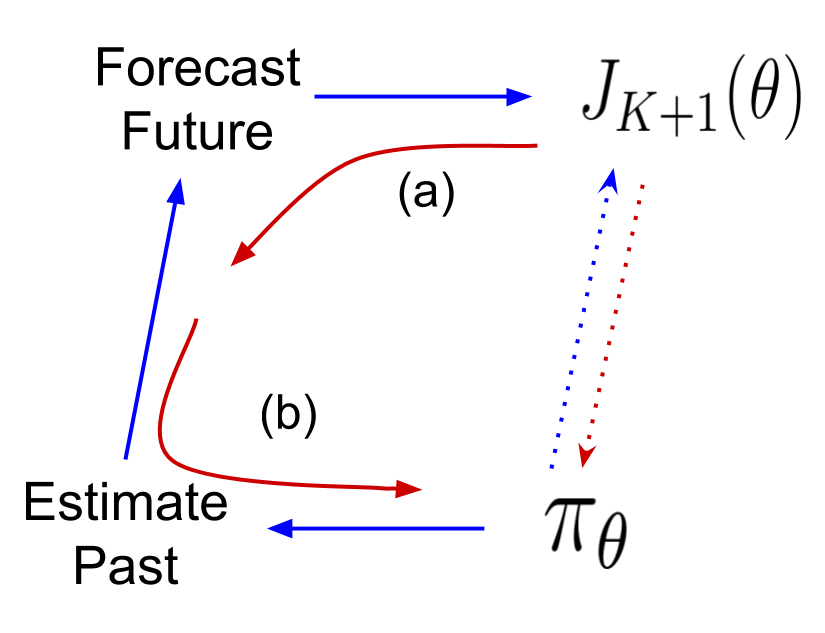
Optimizing for the Future in Non-Stationary MDPs
Yash Chandak,
Georgios Theocharous,
Shiv Shankar,
Martha White,
Sridhar Mahadevan,
Philip Thomas
Thirty-seventh International Conference on Machine Learning (ICML 2020)
Abstract | Arxiv | Blogpost | Code | Video
Most reinforcement learning methods are based upon the key assumption that the transition dynamics and reward functions are fixed, that is, the underlying Markov decision process is stationary. However, in many real-world applications, this assumption is violated, and using existing algorithms may result in a performance lag. To proactively search for a good future policy, we present a policy gradient algorithm that maximizes a forecast of future performance. This forecast is obtained by fitting a curve to the counter-factual estimates of policy performance over time, without explicitly modeling the underlying non-stationarity. The resulting algorithm amounts to a non-uniform reweighting of past data, and we observe that minimizing performance over some of the data from past episodes can be beneficial when searching for a policy that maximizes future performance. We show that our algorithm, called Prognosticator, is more robust to non-stationarity than two online adaptation techniques, on three simulated problems motivated by real-world applications.
|
|
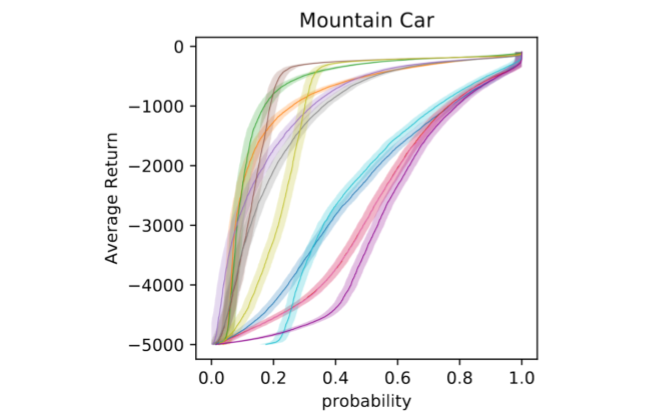
Evaluating the Performance of Reinforcement Learning Algorithms
Scott Jordan,
Yash Chandak,
Daniel Cohen,
Mengxue Zhang,
Philip Thomas
Thirty-seventh International Conference on Machine Learning (ICML 2020)
Abstract | Arxiv | Code | Video
Performance evaluations are critical for quantifying algorithmic advances in reinforcement learning. Recent reproducibility analyses have shown that reported performance results are often inconsistent and difficult to replicate. In this work, we argue that the inconsistency of performance stems from the use of flawed evaluation metrics. Taking a step towards ensuring that reported results are consistent, we propose a new comprehensive evaluation methodology for reinforcement learning algorithms that produces reliable measurements of performance both on a single environment and when aggregated across environments. We demonstrate this method by evaluating a broad class of reinforcement learning algorithms on standard benchmark tasks.
|

|
Lifelong Learning with a Changing Action Set
Yash Chandak,
Georgios Theocharous,
Chris Nota,
Philip Thomas
(Oral) Thirty-fourth AAAI Conference on Artificial Intelligence (AAAI 2020)
Outstanding Student Paper Honorable Mention.
Abstract | Arxiv | Code
In many real-world sequential decision making problems, the number of available actions (decisions) can vary over time. While problems like catastrophic forgetting, changing transition dynamics, changing rewards functions, etc. have been well-studied in the lifelong learning literature, the setting where the action set changes remains unaddressed. In this paper, we present an algorithm that autonomously adapts to an action set whose size changes over time. To tackle this open problem, we break it into two problems that can be solved iteratively: inferring the underlying, unknown, structure in the space of actions and optimizing a policy that leverages this structure. We demonstrate the efficiency of this approach on large-scale real-world lifelong learning problems.
|

|
Reinforcement Learning When All Actions are Not Always Available
Yash Chandak,
Georgios Theocharous,
Blossom Metevier,
Philip Thomas
Thirty-fourth AAAI Conference on Artificial Intelligence (AAAI 2020)
Abstract | Arxiv | Code
The Markov decision process (MDP) formulation used to model many real-world sequential decision making problems does not capture the setting where the set of available decisions (actions) at each time step is stochastic. Recently, the stochastic action set Markov decision process (SAS-MDP) formulation has been proposed, which captures the concept of a stochastic action set. In this paper we argue that existing RL algorithms for SAS-MDPs suffer from divergence issues, and present new algorithms for SAS-MDPs that incorporate variance reduction techniques unique to this setting, and provide conditions for their convergence. We conclude with experiments that demonstrate the practicality of our approaches using several tasks inspired by real-life use cases wherein the action set is stochastic.
|
|
Reinforcement Learning for Strategic Recommendations
Georgios Theocharous,
Yash Chandak,
Philip Thomas,
Frits de Nijs
Technical Report
Abstract | Arxiv
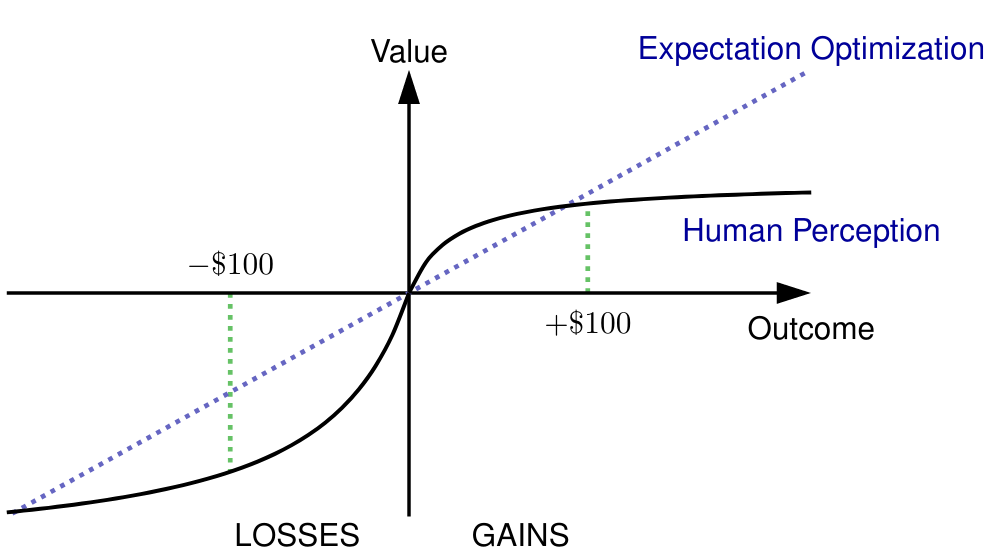
Strategic recommendations (SR) refer to the problem where an intelligent agent observes the sequential behaviors and activities of users and decides when and how to interact with them to optimize some long-term objectives, both for the user and the business. These systems are in their infancy in the industry and in need of practical solutions to some fundamental research challenges. At Adobe research, we have been implementing such systems for various use-cases, including points of interest recommendations, tutorial recommendations, next step guidance in multi-media editing software, and ad recommendation for optimizing lifetime value. There are many research challenges when building these systems, such as modeling the sequential behavior of users, deciding when to intervene and offer recommendations without annoying the user, evaluating policies offline with high confidence, safe deployment, non-stationarity, building systems from passive data that do not contain past recommendations, resource constraint optimization in multi-user systems, scaling to large and dynamic actions spaces, and handling and incorporating human cognitive biases. In this paper we cover various use-cases and research challenges we solved to make these systems practical.
|
|
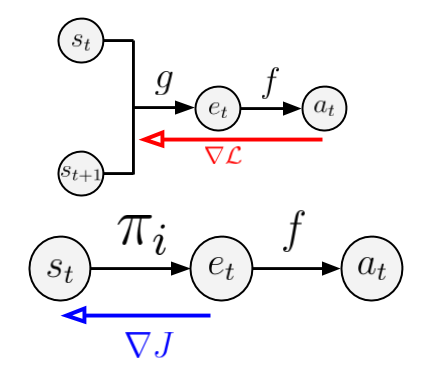
Reinforcement Learning with a Dynamic Action Set
Yash Chandak,
Georgios Theocharous,
James Kostas,
Philip Thomas
Continual Learning workshop at the Thirty-second Conference on Neural Information Processing Systems (NeurIPS 2018)
|

|
Fusion Graph Convolutional Networks
Priyesh Vijayan
Yash Chandak,
Mitesh Khapra,
Srinivasan Parthasarathy,
Balaraman Ravindran
14th International Workshop on Machine Learning with Graphs, 24th ACM SIGKDD Conference on
Knowledge Discovery and Data Mining (KDD 2018).
Abstract | Arxiv | Code
Semi-supervised node classification in attributed graphs, i.e., graphs with node features, involves learning to classify unlabeled nodes given a partially labeled graph. Label predictions are made by jointly modeling the node and its' neighborhood features. State-of-the-art models for node classification on such attributed graphs use differentiable recursive functions that enable aggregation and filtering of neighborhood information from multiple hops. In this work, we analyze the representation capacity of these models to regulate information from multiple hops independently. From our analysis, we conclude that these models despite being powerful, have limited representation capacity to capture multi-hop neighborhood information effectively. Further, we also propose a mathematically motivated, yet simple extension to existing graph convolutional networks (GCNs) which has improved representation capacity. We extensively evaluate the proposed model, F-GCN on eight popular datasets from different domains. F-GCN outperforms the state-of-the-art models for semi-supervised learning on six datasets while being extremely competitive on the other two.
|
|
|
HOPF: Higher Order Propagation Framework for Deep Collective Classification
Priyesh Vijayan
Yash Chandak,
Mitesh Khapra,
Srinivasan Parthasarathy,
Balaraman Ravindran
Eighth International Workshop on Statistical Relational AI at the 27th International Joint Conference on
Artificial Intelligence (IJCAI 2018).
Abstract | Arxiv | Code
Given a graph where every node has certain attributes associated with it and some nodes have labels associated with them, Collective Classification (CC) is the task of assigning labels to every unlabeled node using information from the node as well as its neighbors. It is often the case that a node is not only influenced by its immediate neighbors but also by higher order neighbors, multiple hops away. Recent state-of-the-art models for CC learn end-to-end differentiable variations of Weisfeiler-Lehman (WL) kernels to aggregate multi-hop neighborhood information. In this work, we propose a Higher Order Propagation Framework, HOPF, which provides an iterative inference mechanism for these powerful differentiable kernels. Such a combination of classical iterative inference mechanism with recent differentiable kernels allows the framework to learn graph convolutional filters that simultaneously exploit the attribute and label information available in the neighborhood. Further, these iterative differentiable kernels can scale to larger hops beyond the memory limitations of existing differentiable kernels. We also show that existing WL kernel-based models suffer from the problem of Node Information Morphing where the information of the node is morphed or overwhelmed by the information of its neighbors when considering multiple hops. To address this, we propose a specific instantiation of HOPF, called the NIP models, which preserves the node information at every propagation step. The iterative formulation of NIP models further helps in incorporating distant hop information concisely as summaries of the inferred labels. We do an extensive evaluation across 11 datasets from different domains. We show that existing CC models do not provide consistent performance across datasets, while the proposed NIP model with iterative inference is more robust.
|