I work as a postdoc for Prof. Emma Brunskill at Stanford University.
I received my PhD at the University of Massachusetts, where I was fortunate to be advised by Prof. Philip Thomas.
My Resume/CV can be found here.
Research Interests
Click here for all the publications.
|
Information Directed Search for Formal Reasoning with Large Language Models
Yash Chandak,
Jonathan N. Lee,
Emma Brunskill.
In preparation.
Abstract: Formal reasoning tasks are challenging to solve but often there is availability of rich feedback, unlike a scalar feedback in the classical RL setting. How do we combine LLMs and RL to obtain the best of both for long-horizon (formal) reasoning tasks like theorem proving and code generation?
|
|
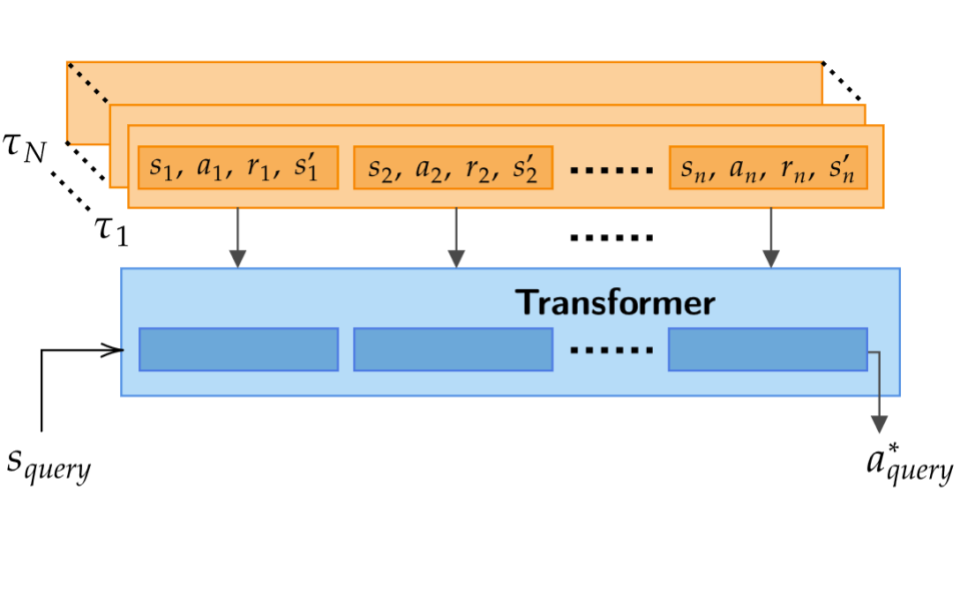
Supervised Pretraining Can Learn In-Context Reinforcement Learning
Jonathan N. Lee,
Annie Xie,
Aldo Pacchiano,
Yash Chandak,
Chelsea Finn,
Ofir Nachum,
Emma Brunskill.
(Spotlight) Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS 2023) | Arxiv
Abstract: Can supervised pre-training provide in-context capabilities to solve decision-making problems? Perhaps surprisingly, drawing formal connections to posterior sampling, in-context interaction with the same model can result in conservative behavior in the offline setting, and also optimistic exploration in the online setting.
|
Strategic Data Collection & Reward Design
|
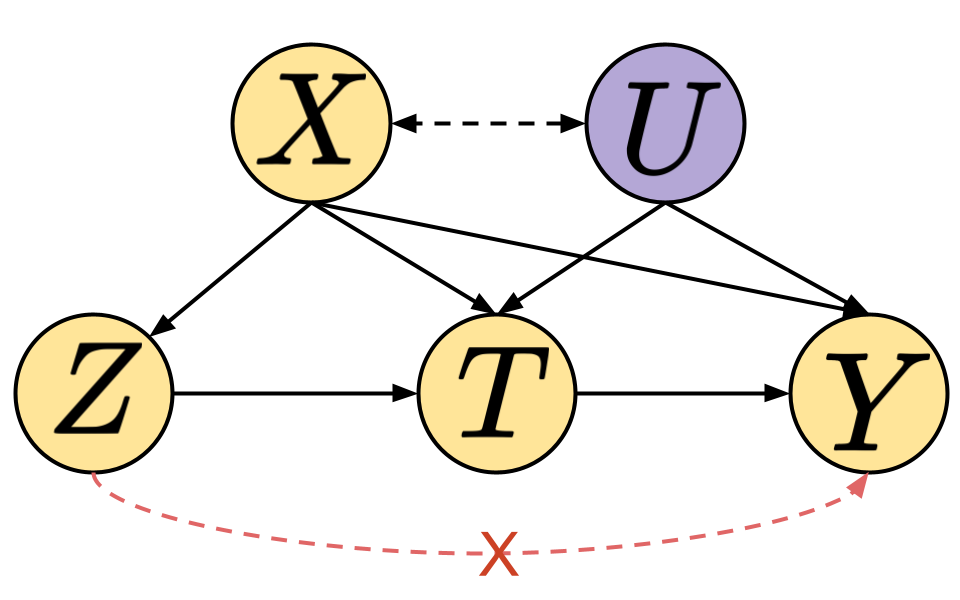
Adaptive Instrument Design for Indirect Experiments
Yash Chandak,
Shiv Shankar,
Vasilis Syrgkanis,
Emma Brunskill.
Twelfth International Conference on Learning Representations (ICLR 2024) | Arxiv
Abstract: In human-AI systems, AI can only be suggestive and not prescriptive about what a human should do (e.g., how should a student interact with LLMs to learn quicker). In such cases, how should AI systems interact strategically to quickly estimate what would have happened had the human complied to its suggestions?
|
|
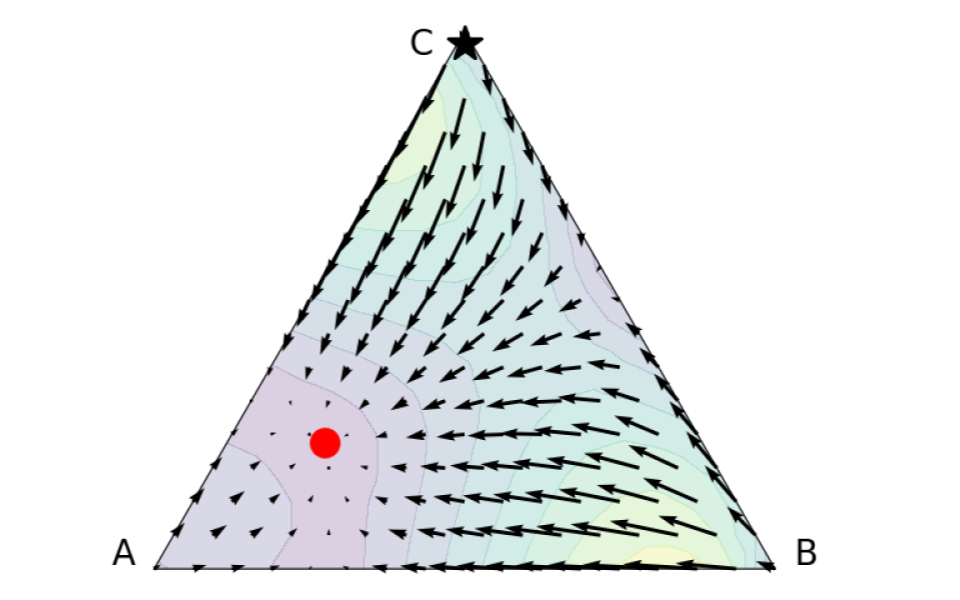
Behavior Alignment via Reward Function Optimization
Dhawal Gupta*,
Yash Chandak*,
Scott Jordan,
Philip Thomas,
Bruno Castro da Silva.
*Equal contribution
(Spotlight) Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS 2023) | Arxiv
Abstract: How should we leverage side-information to design reward functions that are dense, yet aligned with a user's goal? We show that the classic approach of reward shaping has several limitations, and propose a new bi-level reward alignment procedure to address the challenges.
|
